Python基础笔记(3):基本数据类型
标准数据类型
在上个笔记中,我们提及了Python中的六个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Number 数字
Python3 支持 int、float、bool、complex(复数)。
在Python 3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
在 Python3.6+ 中书写很大的数时,可以在任意位置加入下划线,使数字更清晰易读,但是请注意Python3中的数字是没有限制大小的
1 | universe_age= 14_000_000_000 |
bool 是 int 的子类,True 和 False 可以和数字相加, True==1、False==0 会返回True,但可以通过is来判断类型:
1 | 1 is True |
而其他三种则为三种不同的数值类型
三种数
- 整型(
int) : 通常被称为整型或整数 - 浮点型(
float) : 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示2.5e2 - 复数(
complex) : 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示,a和b都将以浮点型存储
互相转换
int(x)将x转换为一个整数。float(x)将x转换到一个浮点数。complex(x)将x转换到一个复数,实数部分为x,虚数部分为0complex(x, y)将x和y转换到一个复数,实数部分为x,虚数部分为y
数值运算
常见的有七种:
1 | 5 + 4 # 加法 |
二、八、十六进制
表示法
- 二进制 :
b;0b110011 - 八进制:
o;0o56432 - 十六进制:
x;0xF765A
互相转换
int("x", y)将x转换为y进制bin(x)将x转换为二进制hex(x)将x转换为十六进制oct(x)将x转换为八进制
String 字符串
Python中的字符串用单引号'或双引号"括起来,同时使用反斜杠\转义特殊字符。
字符串截取
字符串的截取的语法格式如下:
1 | 变量[头下标:尾下标] |
下标值以 0 为开始值,-1 为从末尾的开始位置。
字符转义
Python使用反斜杠\转义特殊字符
如果要使反斜杠不发生转义,则可以在字符串前加r,表示原始字符串:
1 | print('hello\nworld') |
注意点
- 字符串可以用+运算符连接在一起,用*运算符重复
- Python中的字符串不能改变,不能向一个索引位置赋值,例如
word[0] = 'm'会导致错误
格式化字符串
%格式符
与大多数语言的printf()类似,但是他是以%后接的形式
1 | "今天是%d月%d日,天气%s" % (1, 10, "阴") |
format方法
format方法有三种格式化方式
-
按位置顺序填充
1
2hw = "hello {}{}{}"
print(hw.format("wo","rl","d!")) -
按索引值填充
1
2hw = "hello {2}{0}{1}"
print(hw.format("d!","wo","rl")) -
按照关键词填充
1
2hw = "hello {a}{b}{c}"
print(hw.format("wo","rl","d!"))
f-string
f-string称之为字面量格式化字符串,类似于JS框架中的{{ var }}。
它以f开头,后面跟着字符串,字符串中的表达式用大括号{}包起来,它会将变量或表达式计算后的值替换进去:
1 | name = 'Runoob' |
字符串运算
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python"
| 操作符 | 描述 | 实例 |
|---|---|---|
+ |
字符串连接 | a + b 输出结果: HelloPython |
* |
重复输出字符串 | a*2 输出结果:HelloHello |
[] |
通过索引获取字符串中字符 | a[1] 输出结果 e |
[ : ] |
截取字符串 | a[1:4] 输出结果 ell |
in |
成员运算符 - 如果字符串中包含给定的字符返回 True |
'H' in a 输出结果 True |
not in |
成员运算符 - 如果字符串中不包含给定的字符返回 True |
'M' not in a 输出结果 True |
==、!= |
两个字符串是否完全相等 | a!=b 输出结果 True |
>、<、>= 、<= |
依次比较ACSII码 |
a<b 输出结果 True |
List 列表
List(列表) 是 Python 中使用最频繁的数据类型。列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
创建列表
使用中括号 [] 将各个元素括起来即可,元素类型可不相同
1 | list = ['red', 'green', 'blue', 'yellow', 'white'] |
列表截取
-列表截取的语法格式如下:
1 | 变量[头下标:尾下标] |
索引值以 0 为开始值,-1 为从末尾的开始位置,留空为直到最前或者最后一个元素。
列表操作符
-
组合
+1
print([1,2,3] + [4,5,6]) # [1, 2, 3, 4, 5, 6]
-
重复 ‘*’
1
print([1,2,3] * 2) # [1, 2, 3, 1, 2, 3]
-
判断是否存在列表中
in / not in1
2print (3 in [1,2,3]) # True
print (3 not in [1,2,3]) # False
函数与方法
函数
len(list)列表元素个数max(list)返回列表元素最大值min(list)返回列表元素最小值list(seq)将元组转换为列表
方法
增加
list.append(obj)在列表末尾添加新的对象list.extend(seq)在列表末尾追加另一个序列中的多个值list.insert(index, obj)将对象插入列表
删除
list.pop(index)移除列表中的一个元素,默认是最后一个,并返回值(栈的pop)list.remove(obj)移除列表中该对象的第一个匹配值list.clear()清空列表
查找
list.index(obj)查找该对象的第一个匹配值的索引位置
修改
list.reverse()反向列表中的元素list.sort(key=Nome, reverse=False)对列表排序- 直接根据索引修改
统计与复制
list.count(obj)统计对象出现的次数list.copy()复制列表
Tuple 元组
元组与列表类似,区别在于元组的元素不能修改。
创建元组
元组写在小括号 () 里,元素之间用逗号隔开
1 | tuple = ('abc', 123, (456,)) |
元组与字符串类似,可以被索引且下标索引从0开始,-1 为从末尾开始的位置。也可以进行截取。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
注意点
-
string、list 和 tuple 都属于 sequence(序列)
-
构造包含只有一个元素的元组需要在后面添加逗号
1
tup = (123,)
-
元组也可以使用+操作符进行拼接
Set 集合
Python中的集合与数学概念的集合类似,集合中的每一个元素都是独一无二的,是一个无序不重复元素的序列;
由于集合是无序的,因此它不会以特定的顺序储存元素,遍历里面的元素所提取出来的元素的顺序也是不定的。
创建集合
创建集合有两种方法
-
使用大括号
{}1
set = {var1, var2, ...}
-
使用
set()函数该函数可以将其他类型转换为集合或者创建一个空集合。由于
{ }是用于创建一个空的字典的,所以空集合只能通过set()来创建1
2
3
4a = set("12345") # 字符串转集合
b = set(['4', '5', '6', '7', '8']) # 列表转集合
print(a) # ['1', '2', '3', '4', '5']
print(b) # ['4', '5', '6', '7', '8']
集合运算
集合的运算与数学中的运算类似
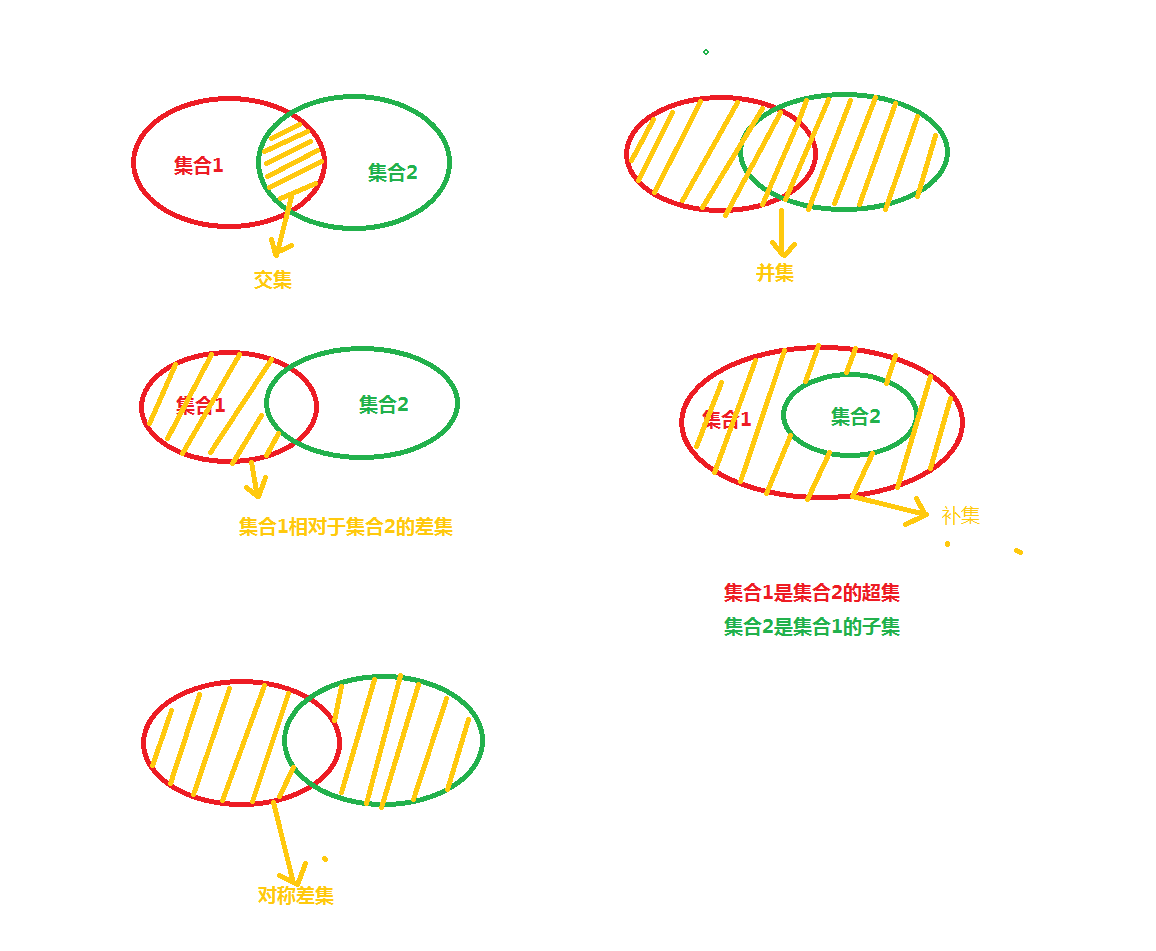
在python中提供了多种运算符与方法进行集合的运算
| 运算符 / 方法 | 描述 |
|---|---|
S & T 或 S.intersaction(T) |
交集。返回一个新集合,包括同时在集合 S 和 T 中的元素 |
S | T 或 S.union(T) |
并集。返回一个新集合,包括集合 S 和 T 中的所有元素 |
S - T 或 S.difference(T) |
差集。返回一个新集合,包括在集合 S 中但不在集合 T 中的元素 |
S ^ T或 s.symmetric_difference(T) |
补集。返回一个新集合,包括集合 S 和 T 中的元素,但不包括同时在其中的元素 |
s <= T 或 S.issubset(T) |
判断子集。如果 S 与 T 相同或 S 是 T 的子集,返回 True ,否则返回 False 。可以用 S < T 判断 S 是否是 T 的真子集 |
S >= Т 或 S.issuperset(T) |
判断超集。如果 S 与 T 相同或 S 是 T 的超集,返回 True ,否则返回 False 。可以用 S > T 判断 S 是否是 T 的真超集 |
集合其他内置方法
统计元素个数
set.len()
添加
set.add(obj, ...)将单个元素添加至集合中set.update(seq, ...)添加一个序列(列表、元组、字典)
删除
set.remove(obj)移除一个元素,找不到时会报错set.discard(obj)移除一个元素,但是找不到时不会报错set.pop()随机移除一个元素,并返回他的值set.clear()清空集合
复制
set.copy()
判断是否存在
1 | x in s |
Dictionary 字典
字典是一种依靠键值对存储数据的容器类模型
创建字典
字典的每个键值key=>value对用冒号:分割,每个对之间用逗号,分割,整个字典包括在花括号{}中
1 | d = {'name': 'IceWindy', 'url': 'www.icewindy.cn'} |
一般而言,为了让代码更可读,我们会写成多行的形式
1 | d = { |
访问字典
key=>value
-
直接使用key当索引
1
2
3
4
5
6
7
8personInfo = {
'name': 'Tom',
'age': 18,
'hobby': ['reading', 'running', 'swimming']
}
print(personInfo['name']) # Tom
print(personInfo['age']) # 18
print(personInfo['hobby']) # ['reading', 'running', 'swimming'] -
使用
get()get()的第一个参数是要查询的键,第二个参数是键不存在时返回的默认值1
2
3
4
5
6
7
8
9
10
11personInfo = {
'name': 'Tom',
'age': 18,
'job': 'student'
}
job = personInfo.get('job', "Tom didn't have a job yet!")
print(job) # student
del personInfo['job']
job = personInfo.get('job', "Tom didn't have a job yet!")
print(job) # Tom didn't have a job yet!
遍历
使用for...in dict.items()/key()/values()即可遍历,后面的三个方法分别是遍历key与value,key,value的
1 | for key , value in favoriteLanguages.items(): |
改变字典
添加、修改
添加与修改的方式都一样,通过字典名[键]=值的方式
1 | favoriteLanguages = { |
删除
删除一对键值对的方式通过del 字典名[键]方式
1 | del favoriteLanguages['jen'] |